- 🚀 探索大型语言模型(LLMs)的智能提升之路 🚀
- 🔍 减少幻觉: 自动事实核查,确保信息准确无误,避免误导。
- 📚 信息摘要: 利用不同层次的提示和“map reduce”方法,高效处理长文档。
- 🔑 信息提取: 通过函数调用,从文档中抽取关键信息。
- 🛠️ 工具集成: 连接外部数据和服务,扩展LLMs的知识边界。
- 💡 推理策略: 应用结构化推理,提升模型的决策能力。
- 📈 本文重点: 从减少幻觉到推理策略,全面提升LLMs的智能水平。
- 🔥 立即开始: 跟随脚步,一起探索如何让LLMs变得更加智能和可靠!
本文将深入探讨如何将大型语言模型(LLMs)的流畅性转化为更加智能、高效和可靠的助手能力。我们的目标是通过使用提示、工具和结构化的推理技巧来增强这些模型。在本文中,我们将通过一系列的示例应用程序来展示这些技术的应用。
首先,我们将关注LLMs的一个主要问题——幻觉内容,并探讨通过自动事实核查来解决这一问题,以减少错误信息的传播。接下来,我们会讨论LLMs的一个重要优势——信息摘要,并探讨如何通过不同层次的提示整合,以及对长文档采用“map reduce”方法来进行摘要。
此外,我们还将探讨如何从文档中提取信息,并通过函数调用来进行信息的整合。这将引导我们进入工具集成的讨论,我们将展示如何将外部数据和服务与LLMs结合,以扩展它们有限的世界知识。最后,我们会通过应用推理策略来进一步扩展这些应用程序。
本文的主要内容将包括以下几个方面:
- 通过事实核查来减少幻觉内容
- 信息摘要技巧
- 文档信息提取方法
- 使用工具来回答问题
- 推理策略的探索
1 - 通过事实核查减少幻觉
在大型语言模型(LLMs)中,幻觉是指生成的文本与输入信息不一致或缺乏意义。这种现象与忠实性相对,后者意味着输出信息与原始来源保持一致性。幻觉可能导致虚假信息、谣言和欺诈性内容的传播,对社会产生诸如科学不信任、意见极端分化和民主程序受损等负面影响。
新闻和档案研究领域对错误信息进行了深入研究。事实核查活动为新闻工作者和独立核查人员提供了培训和资源,使得专家能够进行大规模的验证。处理虚假声明对于保持信息的完整性和对抗其对社会的有害影响至关重要。
自动事实核查是一种应对幻觉的技术,它涉及将LLMs生成的声明与外部来源的证据进行对比验证,以识别出不正确或未经核实的陈述。 事实核查过程主要包括三个步骤:
- 声明识别:找出需要进一步核实的信息部分。
- 证据搜集:寻找能够支持或反驳该声明的资料来源。
- 真实性评估:依据搜集到的证据对声明的真实性做出判断。
在某些情况下,上述过程的第二和第三步也被称为理由生成和结论预测。
下面图表展示了自动事实核查流程的三个阶段概念,图片来源:https://github.com/Cartus/Automated-Fact-Checking-Resources 。
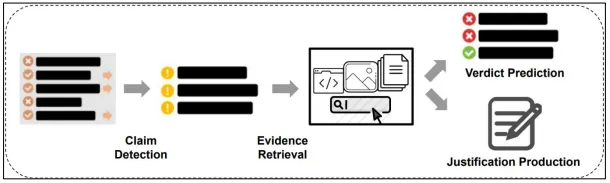
预训练的LLMs拥有丰富的世界知识,可以通过适当的提示来提取事实。同时,可以使用外部工具搜索包括知识库、维基百科、教科书和语料库在内的资源以获取证据。通过将声明依托于数据,事实核查有助于提高LLMs的可信度。
自2018年24层的BERT-Large模型以来,语言模型已在维基百科等大型知识库上进行了预训练,使得它们能够回答来自维基百科或其他来源,如互联网、教科书、arXiv和GitHub的知识点问题。
为了检索作为证据的事实,我们可以通过掩码技术和其他方法对LLMs进行提示。例如,要回答“微软总部的位置在哪里?”这一问题,可以将其改写为“微软的总部在[MASK]”,并输入到语言模型中以获取答案。
我们还可以通过整合外部工具来搜索各种知识库和文档。核心思想是通过将幻觉声明与事实数据源相对照,来验证声明的真实性。
自动事实核查通过确保LLMs的回应与现实世界中的证据相一致,提供了一种提升LLMs可靠性的方法。在接下来的章节中,我们将详细展示这一方法。
LangChain提供了一个事实核查链条,该链条通过提示链技术,使得模型能够主动质疑构成某个声明的假设。在这个自我核查的链条LLMCheckerChain中,模型会连续接收到提示:首先是明确化假设,提示的形式如下:
Here's a statement: {statement}\nMake a bullet point list of theassumptions you made when producing the above statement.\n
这是一个字符串模板,其中花括号中的元素将由变量替换。随后,这些假设将反馈给模型,以便逐一进行核查,提示形式如下:
Here is a bullet point list of assertions:
{assertions}
For each assertion, determine whether it is true or false. If it isfalse, explain why.\n\n
最终,模型需要做出最终判断,提示如下:
In light of the above facts, how would you answer the question
'{question}'
LLMCheckerChain能够独立完成上述所有步骤,例如:
from langchain.chains import LLMCheckerChain
from langchain.llms import OpenAI
llm = OpenAI(temperature=0.7)
text = "What type of mammal lays the biggest eggs?"
checker_chain = LLMCheckerChain.from_llm(llm, verbose=True)
checker_chain.run(text)
模型对于问题“哪种哺乳动物产下最大的卵?”可能返回多种结果,包括错误的以及正确识别为错误的。在尝试过程中,我得到了蓝鲸、北美海狸和已灭绝的巨型恐鸟等答案。正确的答案应该是:
Monotremes, a type of mammal found in Australia and parts of New Guinea,lay the largest eggs in the mammalian world. The eggs of the Americanechidna (spiny anteater) can grow as large as 10 cm in length, anddunnarts (mouse-sized marsupials found in Australia) can have eggs thatexceed 5 cm in length.
• Monotremes can be found in Australia and New Guinea
• The largest eggs in the mammalian world are laid by monotremes
• The American echidna lays eggs that can grow to 10 cm in length
• Dunnarts lay eggs that can exceed 5 cm in length
• Monotremes can be found in Australia and New Guinea – True
• The largest eggs in the mammalian world are laid by monotremes – True
• The American echidna lays eggs that can grow to 10 cm in length – False,the American echidna lays eggs that are usually between 1 to 4 cm inlength.
• Dunnarts lay eggs that can exceed 5 cm in length – False, dunnarts layeggs that are typically between 2 to 3 cm in length.
The largest eggs in the mammalian world are laid by monotremes, which canbe found in Australia and New Guinea. Monotreme eggs can grow to 10 cm inlength.
> Finished chain
尽管这种技术不能保证答案都正确,但它可以阻止某些错误结果的产生。事实核查方法涉及将声明拆解为更小的、可核查的查询,这些查询可以被构建成问答任务。专门设计用于搜索特定领域数据集的工具可以有效地协助事实核查者找到证据。现成的搜索引擎,如Google和Bing,也能够检索到与主题和证据相关的内容,以准确捕捉声明的真实性。我们将采用这种方法,通过网络搜索和其他本文介绍的应用来返回结果。
接下来,我们将探讨自动化总结文本和较长文档,例如研究论文的过程。
2 - 信息摘要
在快速变化的商业和研究环境中,要跟上不断增长的信息量是一项挑战。对于计算机科学和人工智能等技术领域的专业人员来说,跟上最新的进展是非常关键的。但是,阅读和理解大量的文献既耗时又辛苦。为了解决这个问题,自动化技术提供了帮助。工程师们通过设计和创新,创建了各种流程和管道,以自动化这些重复性的工作,从而避免它们。这种策略虽然有时会被误解为懒惰,但实际上它让工程师能够将精力集中在更复杂的难题上,并更高效地运用他们的专业技能。
大型语言模型(LLMs)因其出色的语言理解能力而在文本压缩方面表现出色。本文将探讨使用LangChain进行信息摘要的技术,并逐步介绍不同复杂度级别的方法。
1)基础提示
基础提示是进行简短文本总结的有效方法。我们可以通过设定所需的长度并输入文本来指导大型语言模型(LLM)进行总结。例如,使用LangChain库中的OpenAI模块,可以构建一个简单的提示模板,将文本替换为需要总结的内容。
from langchain import OpenAI
prompt = """
用一句话概括这段文本:
{text}
"""
llm = OpenAI()
summary = llm(prompt.format(text=text))
LangChain装饰器语法提供了一种更接近Python风格的接口,使得定义和执行提示更加简单。LangChain装饰器库在安装LangChain时应该已经一并安装。
使用LangChain装饰器,我们可以将提示文档转换为可执行代码,实现多行定义和更自然的代码流程。例如,以下是一个使用装饰器进行文本总结的示例:
from langchain_decorators import llm_prompt
@llm_prompt
def summarize(text:str, length="short") -> str:
"""
用{length}长度概括这段文本:
{text}
"""
return
summary = summarize(text="让我告诉你一个我年轻时的无聊故事...")
执行上述函数后,得到的摘要结果可能是:“讲述者即将分享他们年轻时的故事。”这个例子展示了如何使用LangChain装饰器以Python风格编写提示,同时在后台处理提示的复杂性,让开发者能够更专注于创造有效的提示。LangChain装饰器通过提供这种直观的接口,使得开发人员能够更容易地利用LLM的能力。
2)提示模板
提示模板是一种用于动态输入的技术,它允许用户将文本嵌入到预先设定的提示中。这种模板不仅支持变化的长度限制,还允许进行模块化的提示设计。
以下是使用LangChain表达式语言(LCEL)实现提示模板的方法:
from langchain import PromptTemplate, OpenAI
from langchain.schema import StrOutputParser
llm = OpenAI()
prompt = PromptTemplate.from_template("Summarize this text: {text}?")
runnable = prompt | llm | StrOutputParser()
summary = runnable.invoke({"text": "这里是要总结的文本内容"})
LCEL通过提供一种声明式的方式来组合不同的处理步骤,使得编写代码更为直观和高效。LCEL的主要优势包括内建的异步处理、批量处理、流处理、备选方案处理、并行处理功能,以及与LangSmith追踪系统的无缝集成。
在此例中,runnable代表一个链条,提示模板、大型语言模型(LLM)和输出解析器被依次连接,形成了一个处理流程。
3)密度链(CoD)
Salesforce的研究人员开发了一种名为“密度链”(Chain of Density, CoD)的新技术,这是一种通过提示引导的方法,用于逐步提高GPT-4生成摘要的信息密度,同时还能控制其长度。
使用CoD技术时,会有一个特定的提示模板,该模板可以根据不同内容和应用场景进行调整和定制。
这是使用CoD的提示:
template = """Article: { text }
You will generate increasingly concise, entity-dense summaries of theabove article.
Repeat the following 2 steps 5 times.
Step 1. Identify 1-3 informative entities (";" delimited) from the articlewhich are missing from the previously generated summary.
Step 2. Write a new, denser summary of identical length which covers everyentity and detail from the previous summary plus the missing entities.
A missing entity is:
- relevant to the main story,
- specific yet concise (5 words or fewer),
- novel (not in the previous summary),
- faithful (present in the article),
- anywhere (can be located anywhere in the article).
Guidelines:
- The first summary should be long (4-5 sentences, ~80 words) yet highlynon-specific, containing little information beyond the entities markedas missing. Use overly verbose language and fillers (e.g., "this articlediscusses") to reach ~80 words.
- Make every word count: rewrite the previous summary to improve flow andmake space for additional entities. - Make space with fusion, compression, and removal of uninformativephrases like "the article discusses".
- The summaries should become highly dense and concise yet self-contained,i.e., easily understood without the article.
- Missing entities can appear anywhere in the new summary.
- Never drop entities from the previous summary. If space cannot be made,add fewer new entities. Remember, use the exact same number of words for each summary.
Answer in JSON. The JSON should be a list (length 5) of dictionaries whosekeys are "Missing_Entities" and "Denser_Summary".
""
CoD提示首先让GPT-4等高级大型语言模型生成一个初始的、信息量较少且表述较为冗长的摘要,该摘要仅包含少数几个实体。随后,CoD通过迭代过程识别出缺失的1至3个实体,并将这些实体融合进重写的摘要中,且保持相同的字数。 这种在长度限制条件下的重复重写过程,促使模型逐步提升抽象级别、合并细节,并进行压缩,以便为后续步骤中的更多实体留出空间。研究者们通过计算实体密度和源句对齐等统计数据来衡量这一密集化过程的效果。
经过五轮迭代,生成的摘要在字数不变的情况下,通过创造性的重写,使得每个词元中包含的实体数量显著增加,从而实现了高度的信息浓缩。研究团队还通过进行人类偏好测试和GPT-4评分来评估不同密度水平下整体质量的变化。
研究发现,通过增加密度可以提高信息量,但如果压缩过度,则会导致连贯性下降。因此,最佳密度是在简洁性和清晰度之间找到平衡点,避免过多的实体影响表达。这项研究不仅展示了如何控制人工智能文本生成中的信息密度,还为未来的研究提供了有价值的见解。
鼓励大家亲自尝试并体验CoD技术!
4)Map-Reduce流水线
LangChain支持Map-Reduce方法,通过大型语言模型(LLMs)对文档进行高效处理和分析。该方法允许将长文档分割成适合LLM处理的小块,独立地对这些块进行摘要,然后再进行合并,实现对任意长度文本的摘要处理。
处理文档的关键步骤包括:
- Map阶段:每个文档独立通过一个摘要链(LLM链)。
- 折叠阶段(可选):将各个文档的摘要合并为一个单一文档。
- Reduce阶段:合并后的文档再次通过LLM链,最终生成输出结果。
Map步骤将链并行应用于每个文档,而Reduce步骤则聚合这些输出,形成最终结果。在必要时,可以递归地执行可选的折叠步骤,以确保数据不超过序列长度限制。
下面的图中进行了说明Map-Reduce链条:
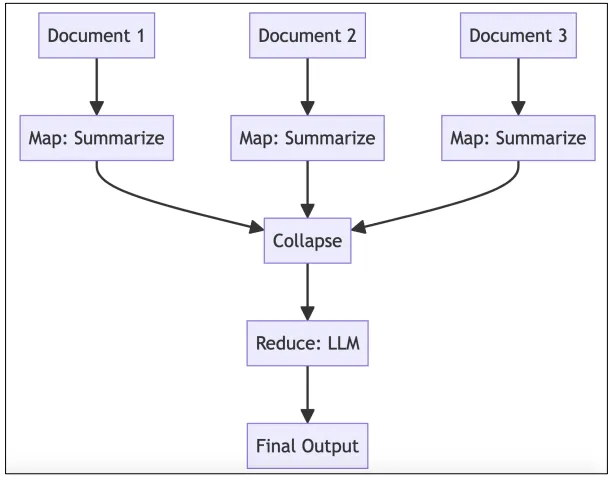 图4.2:LangChain中的Map-Reduce链条
图4.2:LangChain中的Map-Reduce链条
LangChain的Map-Reduce链条方法允许文档的并行处理,并能够利用LLMs对单个文档进行推理、生成或分析,并将它们的输出结合起来。
以下是一个加载PDF文档并进行摘要的示例代码:
from langchain.chains.summarize import load_summarize_chain
from langchain import OpenAI
from langchain.document_loaders import PyPDFLoader pdf_file_path = ""
pdf_loader = PyPDFLoader(pdf_file_path)
docs = pdf_loader.load_and_split()
llm = OpenAI()
chain = load_summarize_chain(llm, chain_type="map_reduce")
chain.run(docs)
Map和Reduce步骤的默认提示是以下这样:
Write a concise summary of the following:
{text}
CONCISE SUMMARY:
Map和Reduce步骤可以使用默认提示,也可以为每个步骤指定自定义提示。在GitHub上开发的文本摘要应用程序展示了如何传递不同的提示。在LangChainHub上,可以看到问答与源提示,它需要一个特定的reduce/combine提示:
Given the following extracted parts of a long document and a question,create a final answer with references (\"SOURCES\"). \nIf you don't knowthe answer, just say that you don't know. Don't try to make up an answer.\ nALWAYS return a \"SOURCES\" part in your answer.\n\nQUESTION: {question}\ n=========\nContent: {text}
摘要文本将来源于Map步骤,而具体的指令可以帮助减少幻觉的发生。其他的指令示例可能包括将文档翻译成不同的语言或以特定风格进行改写。
通过改变提示,我们可以从文档中回答任何问题。这可以构建成一个自动化工具,快速将长文本内容总结成更易消化的格式。GitHub仓库中的摘要包展示了如何关注响应的不同视角和结构。
该工具能够以更简洁和简化的方式总结论文的核心论断、含义和机制,甚至回答有关论文的具体问题,成为文献综述和加速科学研究的宝贵资源。总体上,这种方法旨在为研究人员提供一种更有效和易于访问的方式来跟进最新的研究动态。
使用LangChain进行有效的提示工程,可以利用LLMs实现强大的摘要功能。一些实用的建议包括: • 从简单方法开始,必要时再采用Map-Reduce方法 • 调整块大小以平衡上下文限制和并行处理的需求 • 为获得最佳结果定制Map和Reduce步骤的提示 • 压缩或递归地减少块以适应上下文限制
特别是当我们在Map步骤中进行大量调用时,如果使用了云服务提供商,我们会看到令牌数量和成本的增加。因此,需要对此给予适当的关注。
5)监控令牌使用情况
在使用大型语言模型(LLMs)进行操作,特别是执行诸如map操作这样的长循环任务时,监控令牌使用情况并掌握花费情况至关重要。
对于生成型AI的严肃用途,了解不同语言模型的功能、定价方案和用例是必要的。云服务提供商提供了多种模型,以满足不同的自然语言处理(NLP)需求。以OpenAI为例,它提供了适合解决复杂NLP问题的强大语言模型,并基于使用的令牌大小和数量提供灵活的定价选项。
ChatGPT模型,如GPT-3.5-Turbo,专注于对话应用,例如聊天机器人和虚拟助手,擅长生成准确流畅的响应。
InstructGPT系列中的模型,如Ada和Davinci,旨在遵循单轮指令,它们在速度和处理能力上各有侧重。Ada是速度最快的模型,适合对速度有高要求的应用场景,而Davinci则是最强大的模型,能够处理更为复杂的指令。模型的定价取决于其能力,从成本较低的Ada到价格较高的Davinci不等。
OpenAI还提供了DALL·E、Whisper和其他API服务,用于图像生成、语音转录、翻译和语言模型访问等多种应用。
DALL·E是一个AI驱动的图像生成模型,可以集成到应用程序中,用于创造和编辑新颖的图像和艺术作品。OpenAI提供不同分辨率的选项,用户可以根据需要选择细节层次。图片的价格会根据所选分辨率有所不同。
Whisper是一款能够将语音转录为文本并翻译成英语的AI工具,有助于记录对话、促进交流,并提高跨语言的理解。使用Whisper的成本按分钟计费。
通过OpenAI回调,我们可以跟踪OpenAI模型中的令牌使用情况:
from langchain import OpenAI, PromptTemplate
from langchain.callbacks import get_openai_callback
llm_chain = PromptTemplate.from_template("Tell me a joke about {topic}!")| OpenAI()
with get_openai_callback() as cb:
response = llm_chain.invoke(dict(topic="light bulbs"))
print(response)
print(f"Total Tokens: {cb.total_tokens}")
print(f"Prompt Tokens: {cb.prompt_tokens}")
print(f"Completion Tokens: {cb.completion_tokens}")
print(f"Total Cost (USD): ${cb.total_cost}")
使用LangChain提供的OpenAI和PromptTemplate,以及get_openai_callback回调函数,可以捕获并打印出总令牌数、提示令牌数、完成令牌数以及总花费。
Q: How many light bulbs does it take to change people's minds?
A: Depends on how stubborn they are!
Total Tokens: 36
Prompt Tokens: 8
Completion Tokens: 28
Total Cost (USD): $0.00072
此外,llm类的generate()方法返回的是一个LLMResult对象,其中包含了令牌使用情况和完成原因等信息。
input_list = [
{"product": "socks"},
{"product": "computer"},
{"product": "shoes"}
]
llm_chain.generate(input_list)
OpenAI API中的chat completions响应格式也包含了一个usage对象,提供了完成令牌、提示令牌和总令牌的具体数值。
{
"model": "gpt-3.5-turbo-0613",
"object": "chat.completion",
"usage": {
"completion_tokens": 17,
"prompt_tokens": 57,
"total_tokens": 74
}
}
这些信息对于理解应用程序各部分的花费非常重要。
接下来,我们将探讨如何使用LangChain结合OpenAI函数从文档中提取特定信息。
3 - 从文档中提取信息
在2023年6月,OpenAI对其API进行了更新,引入了函数调用的新功能,这一更新基于指令调整,允许开发者通过模式描述来调整大型语言模型(LLMs),使其能够返回符合预定义模式的结构化输出。例如,通过输出预定义的JSON格式文本来提取文本中的实体。
这项新功能扩展了开发者的能力,使其能够创建能够利用外部工具或OpenAI插件回答问题的聊天机器人,同时也支持将自然语言查询转换为API或数据库查询,从而从文本中抽取结构化数据。
开发者现在可以向gpt-4-0613和gpt-3.5-turbo-0613模型描述函数,使模型能够生成包含调用这些函数所需参数的JSON对象。这一特性旨在加强GPT模型与外部工具和API的连接,为从模型检索结构化数据提供了一种可靠的方法。
更新的实现机制涉及到在/v1/chat/completions端点使用新的API参数——函数。这个函数参数通过名称、描述、参数和函数体本身来定义。开发者可以使用JSON模式向模型描述函数,并指定所需的函数调用。
在LangChain中,我们可以利用OpenAI的函数调用来提取信息或调用插件。在信息提取方面,我们可以从文本和文档中获取特定实体及其属性,并在OpenAI聊天模型的提取链中使用它们。例如,这可以帮助识别文本中提及的人物。通过使用OpenAI的函数参数并定义一个模式,可以确保模型输出所需的实体和属性及其相应的类型。
这种方法的优势在于,它允许通过定义一个包含所需属性及其类型的模式来精确提取实体。同时,它还允许指定哪些属性是必需的,哪些是可选的。
模式的默认格式是字典,但我们也可以使用Pydantic——一个流行的解析库来定义属性及其类型,这为提取过程提供了控制和灵活性。
以下是一个简历(CV)信息所需模式的示例:
from typing import Optional
from pydantic import BaseModel
class Experience(BaseModel):
start_date: Optional[str]
end_date: Optional[str]
description: Optional[str]
class Study(Experience):
degree: Optional[str]
university: Optional[str]
country: Optional[str]
grade: Optional[str]
class WorkExperience(Experience):
company: str
job_title: str
class Resume(BaseModel):
first_name: str
last_name: str
linkedin_url: Optional[str]
email_address: Optional[str]
nationality: Optional[str]
skill: Optional[str]
study: Optional[Study]
work_experience: Optional[WorkExperience]
hobby: Optional[str]
我们可以利用这个模式从简历中提取信息。通过导入配置模块并执行setup_environment()来简化操作。
from config import setup_environment
setup_environment()
这是一个来自GitHub的示例简历:
 图4.3:示例简历的摘录
图4.3:示例简历的摘录
我们将尝试从这份简历中解析信息。使用LangChain的create_extraction_chain_pydantic()函数,输入我们的模式,将得到一个符合该模式的实例化对象。简单来说,可以尝试以下代码片段:
from langchain.chains import create_extraction_chain_pydantic
from langchain.chat_models import ChatOpenAI
from langchain.document_loaders import PyPDFLoader
pdf_file_path = ""
pdf_loader = PyPDFLoader(pdf_file_path)
docs = pdf_loader.load_and_split()
# please note that function calling is not enabled for all models!
llm = ChatOpenAI(model_name="gpt-3.5-turbo-0613")
chain = create_extraction_chain_pydantic(pydantic_schema=Resume, llm=llm)
chain.run(docs)
请注意,pdf_file_path变量应为PDF文件的相对或绝对路径。我们期望得到的输出可能如下:
[Resume(first_name='John', last_name='Doe', linkedin_url='linkedin.com/ in/john-doe', email_address='[email protected]', nationality=None, skill='React', study=None, work_experience=WorkExperience(start_date='May 2023', end_date='Present', description='Lead a cross-functional team of 5 engineers in developing a search bar, which enables thousands of daily active users to search content across the entire platform. Create stunning home page product demo animations that drives up sign up rate by 20%. Write clean code that is modular and easy to maintain while ensuring 100% test coverage.', company='ABC Company', job_title='Software Engineer'), hobby=None)]
尽管这个结果并不完美——只解析出了一条工作经验,但鉴于我们目前的工作量,这已经是一个不错的开始。完整的示例可以在GitHub仓库中找到。我们可以增加更多功能,比如预测个性或领导能力。
OpenAI以特定语法将这些函数调用注入到系统消息中,这与它们的模型优化方式相匹配。这意味着函数调用会计入上下文限制,并且按照输入令牌相应计费。
LangChain原生支持将函数调用作为提示注入,这使得我们可以使用OpenAI之外的其他提供商的模型在LLM应用程序中进行函数调用。我们将在本节中探讨这一点,并使用Streamlit构建交互式Web应用程序。
指令调整和函数调用允许模型生成可调用的代码,这促进了工具集成,使得LLM代理能够执行这些函数调用来将LLM与实时数据、服务和运行时环境相连接。在下一节中,我们将讨论工具如何通过检索外部知识源来增强上下文,从而提升理解力。
4 - 使用工具回答问题
大型语言模型(LLMs)通常在广泛的语料库上进行训练,这使得它们在处理特定领域任务时可能不够高效。LLMs本身无法与外部环境互动或获取外部数据,但LangChain平台提供了创建能够访问实时信息并执行各种任务的工具的可能性,如天气预报、预订服务、推荐食谱和管理日常任务等。这些工具在代理和链条的框架下运作,使得由LLMs驱动的应用程序能够具备数据意识和代理性,从而扩展了LLMs的应用范围,并使它们变得更加强大和多功能。
工具的一个关键特性是它们能够专注于特定领域或处理特定类型的输入。例如,LLMs本身不具备数学计算的能力,但结合了计算器这样的数学工具后,它们可以接受数学表达式作为输入,并计算出结果。这样,LLMs结合数学工具就能够执行计算任务并提供准确的答案。
工具还能够利用上下文对话来搜索与用户查询相关的数据源,如对于历史事件的问题,工具可以检索Wikipedia上的相关文章来增强对话的上下文。通过利用实时数据来提供回答,工具有助于减少错误或不准确的信息,使得聊天机器人的回答更加有用、正确,并且与现实世界的知识相符合。此外,工具的使用为LLMs解决各种问题提供了创造性的解决方案,并为LLMs在不同领域的应用开拓了新的可能性。例如,可以开发工具使LLMs能够执行高级检索搜索、查询数据库、自动化电子邮件撰写或处理电话通话等功能。
现在,让我们通过一个实际的例子来展示这一过程。
1)使用工具进行信息检索
在LangChain平台中,我们可以使用多种工具,如果这些工具还不足以满足需求,我们还可以轻松地开发自己的工具。以下是一个配置了多种工具的代理示例:
from langchain.agents import (
AgentExecutor, AgentType, initialize_agent, load_tools
)
from langchain.chat_models import ChatOpenAI
def load_agent() -> AgentExecutor:
llm = ChatOpenAI(temperature=0, streaming=True)
# DuckDuckGoSearchRun, wolfram alpha, arxiv search, wikipedia
# TODO: try wolfram-alpha!
tools = load_tools(
tool_names=["ddg-search", "wolfram-alpha", "arxiv", "wikipedia"],
llm=llm
)
return initialize_agent(
tools=tools, llm=llm, agent=AgentType.ZERO_SHOT_REACT_DESCRIPTION, verbose=True
)
这个设置的函数返回一个名为AgentExecutor的链条对象,它允许我们将该代理集成到更大的链条中。Zero-Shot代理是一个多用途的动作代理,我们将在后续部分进一步讨论。
请注意,在ChatOpenAI构造器中有一个名为streaming的参数,我们将其设置为True。这样的设置可以提升用户体验,因为它使得文本响应能够实时更新,而不是等到整个文本生成完毕后才显示。目前,支持流式传输功能的实现包括OpenAI、ChatOpenAI和ChatAnthropic。
所有这些工具都有其专门的用途,并且它们的描述信息会被传递给语言模型。以下是已经集成到代理中的一些工具:
- DuckDuckGo:一个注重隐私的搜索引擎,开发者无需注册即可使用。
- Wolfram Alpha:一个结合了自然语言处理和数学计算能力的集成工具,适用于解决数学问题。
- arXiv:一个搜索学术预印本文献的工具,非常适合回答研究性质的问题。
- Wikipedia:一个涵盖广泛知名实体信息的百科全书,适用于回答与之相关的查询。
要使用Wolfram Alpha工具,用户需要创建一个账户,并设置WOLFRAM_ALPHA_APPID环境变量,该变量应包含用户在Wolfram Alpha官方网站上获取的开发人员令牌。请注意,Wolfram Alpha的网站有时可能会响应较慢,因此注册过程可能需要一些耐心。
除了DuckDuckGo,LangChain还集成了其他多种搜索工具,包括Google、Bing搜索引擎以及元搜索引擎。此外,还有Open-Meteo这样的天气信息集成工具,尽管天气信息也可以通过搜索引擎获得。
2)构建可视化界面
在利用LangChain开发智能代理之后,将其部署到用户友好的应用程序中是顺理成章的下一步。Streamlit作为一个为机器学习工作流优化的开源平台,为实现此目标提供了完美的框架。它可以轻松地将我们的代理封装进一个交互式网络应用程序中。现在,让我们通过Streamlit应用程序来提供我们的代理服务。
为了构建这个应用程序,我们需要用到Streamlit、unstructured、docx等库。
我们可以使用刚刚定义的load_agent()函数来编写应用程序的代码:
import streamlit as st
from langchain.callbacks import StreamlitCallbackHandler
chain = load_agent()
st_callback = StreamlitCallbackHandler(st.container())
if prompt := st.chat_input():
st.chat_message("user").write(prompt)
with st.chat_message("assistant"):
st_callback = StreamlitCallbackHandler(st.container())
response = chain.run(prompt, callbacks=[st_callback])
st.write(response)
在调用链条时,我们使用了回调处理器,这意味着我们可以实时看到模型返回的响应。可以通过以下命令从终端本地启动应用程序:
PYTHONPATH=. streamlit run question_answering/app.py
我们可以在网络浏览器中打开应用程序。下面是应用程序界面的截图示例:
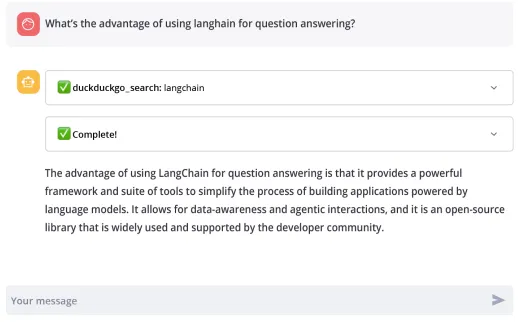
Streamlit应用程序的部署可以是本地的,也可以部署在服务器上。此外,我们还可以将其部署到Streamlit社区云或Hugging Face Spaces上。对于Streamlit社区云,我们只需创建一个GitHub仓库,然后在Streamlit社区云中创建新应用程序并选择该仓库即可。至于Hugging Face Spaces,我们需要创建一个GitHub仓库,并在Hugging Face网站上创建账户,然后进入Spaces创建新空间,并选择我们的仓库。
尽管搜索功能运行良好,但根据所使用的工具,有时可能得到错误的结果。例如,在使用DuckDuckGo搜索“产最大蛋的哺乳动物”时,可能会得出鸵鸟是产最大蛋的哺乳动物的结论,尽管鸭嘴兽有时也会被提及。
以下是正确推理的日志输出示例:
> Entering new AgentExecutor chain...
I'm not sure, but I think I can find the answer by searching online.
Action: duckduckgo_search
Action Input: "mammal that lays the biggest eggs"
Observation: Posnov / Getty Images. The western long-beaked echidna ...
Final Answer: The platypus is the mammal that lays the biggest eggs.
> Finished chain.
通过使用强大的自动化和问题解决框架,我们可以将原本需要数百小时的工作量压缩到几分钟内完成。你可以尝试不同的研究问题,以观察工具是如何被应用的。本书的GitHub仓库提供了实际的实现方式,允许你尝试不同的工具,并有自我验证的选项。
构建Streamlit应用程序有几个关键优势:
- 快速创建聊天机器人的直观图形界面,无需构建复杂前端。Streamlit自动处理输入字段、按钮和交互式控件等元素。
- 将代理的功能无缝集成到特定用例的应用程序中,如客户支持或研究协助,界面可定制以匹配特定领域。
- Streamlit应用程序实时运行Python代码,实现与代理后端API的无缝连接,无额外延迟。
- 易于共享和部署,支持开源GitHub仓库、个人Streamlit共享链接和Streamlit社区云,实现即时发布和分发。
- Streamlit针对模型运行和数据工作流的优化性能,确保即使在处理大型模型时也能保持响应性,使聊天机器人能够优雅地扩展。
- 最终得到的是一个优雅的网络界面,用户可以自然地与我们的LLM驱动代理进行交互,Streamlit在后台处理复杂性。
虽然我们的LLM应用程序能够回答简单问题,但其推理能力仍有限制。在下一节中,我们将实现更高级的代理类型。
5 - 探索推理策略
大型语言模型(LLMs)擅长于数据模式识别,但在处理需要符号推理的复杂多步骤问题时却面临挑战。为了提升研究助理的能力,我们需要实施更高级的推理策略。通过结合神经网络的模式补全和有意识的符号操作,混合系统能够实现包括但不限于以下技能:从一系列事实中进行多步骤演绎推理、通过一系列变换解决方程的数学推理、将问题分解为优化行动序列的规划策略。
通过将工具与明确的推理步骤相结合,而不仅仅依赖于模式补全,我们的代理能够处理需要抽象思维和创造力的问题。这样的代理能够更深入地理解世界,从而在讨论复杂概念时进行更有意义的对话。
以下是通过工具和推理增强LLMs的图示(来源:https://github.com/billxbf/ReWOO ,Binfeng Xu等人,2023年5月,论文《为高效增强语言模型资源而解耦观察与推理》的实现):
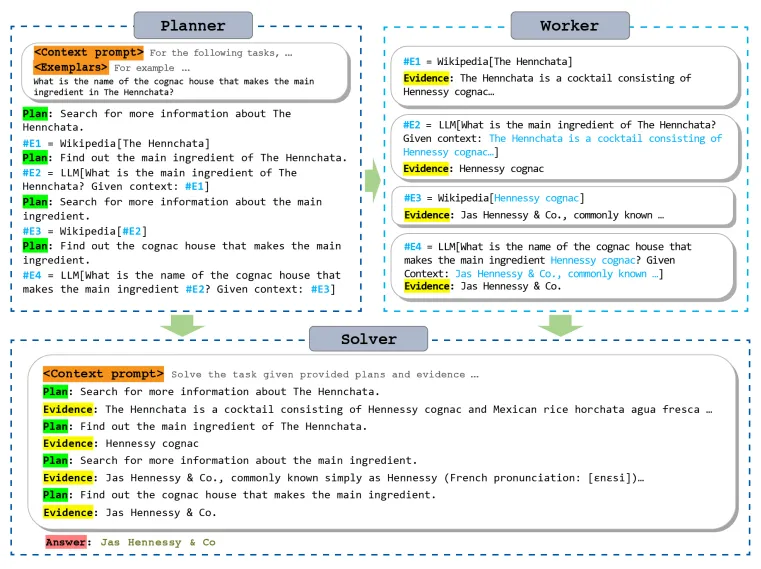
工具增强的LLM范式通过结合搜索引擎、数据库等资源来提升LLMs的推理能力。LLMChain生成文本提示并解析输出以确定下一步行动,而代理类则根据LLMChain的输出来决定采取的行动。此外,通过代理的使用,可以进一步增强这种推理能力。
LangChain由工具、大型语言模型链(LLMChain)和代理三个核心部分组成。 代理的架构主要有两种: (1)动作代理,它根据每次动作后的观察进行迭代推理; (2)计划并执行代理,它会在采取行动前制定完整计划。
在依赖观察的推理模式下,代理会连续地向大型语言模型(LLM)提供上下文信息和示例,以便生成思考和行动。工具的观察结果被用来通知接下来的推理步骤,这一方法应用于动作代理。与此同时,存在一种计划并执行的代理方法,它们会先制定完整的计划,再搜集证据以执行计划。规划者LLM会生成一系列计划(P),代理随后利用工具搜集相应的证据(E),之后将计划和证据一起输入到求解器LLM,以产生最终结果。计划并执行的方法将计划阶段与执行阶段区分开,允许使用更小型的专业化模型来担任规划者和求解器的角色。然而,这种方法需要更多的前期规划工作。下面的图表展示了基于观察的推理模式(来源: https://arxiv.org/abs/2305.18323 ,Binfeng Xu等人,2023年5月)。
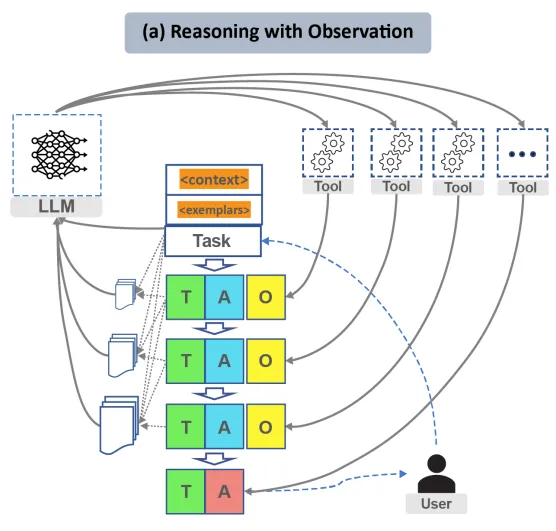
在依赖观察的推理过程中,代理基于当前知识状态或通过观察得到的信息来做出决策、预测或选择。每一轮迭代中,代理都会向大型语言模型(LLM)提供情境和示例,以便启动推理。用户的任务与这些情境和示例结合后,会传递给LLM进行推理。LLM在生成了思考和行动后,会等待工具的观察结果。随后,观察结果将被添加到提示中,以触发对LLM的新一轮调用。在LangChain框架中,这种类型的代理被称为动作代理,或者零射击代理(ZERO_SHOT_REACT_DESCRIPTION),当你创建一个代理时,这是默认的设置。此外,行动之前可以预先制定计划,这种策略在LangChain中被称为计划并执行代理,其概念图可以在提供的链接中查看(来源:https://arxiv.org/abs/2305.18323 ,Binfeng Xu等人,2023年5月)。
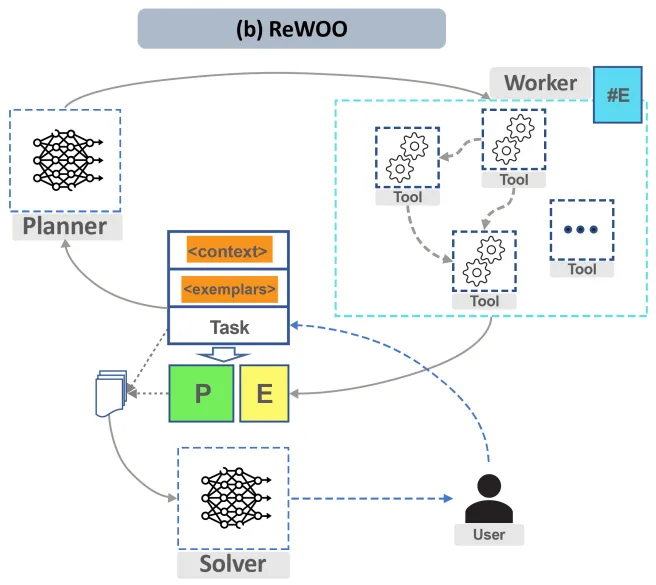
在LangChain中,经过微调以适应规划和工具使用的规划者大型语言模型(LLM)会生成一系列计划(P),并指示代理(即工作者)利用工具收集相应的证据(E)。接着,这些计划和证据将与任务相结合,共同输入至求解器LLM,以产生最终答案。整个过程可以通过以下伪算法描述:
- 使用规划者LLM确定所有必要的步骤。
- 对于每一步,选择并执行适当的工具以实现该步骤。 规划者和求解器可以是两个不同的语言模型,这种方式允许我们为规划者和求解器使用更小型、更专业的模型,并减少每次调用所需的令牌数量。
现在,我们可以着手在研究应用中实现计划和求解的功能。
首先,我们需要在load_agent()函数中增加一个名为strategy的变量,它有两个可能的取值:plan-and-solve或zero-shot-react。在zero-shot-react模式下,应用程序的逻辑保持原样。而在plan-and-solve模式下,我们需要定义一个规划器和执行器,并利用它们构建一个PlanAndExecute代理执行器:
from typing import Literal
from langchain.agents import initialize_agent, load_tools, AgentType
from langchain.chains.base import Chain
from langchain.chat_models import ChatOpenAI
from langchain_experimental.plan_and_execute import (
load_chat_planner, load_agent_executor, PlanAndExecute
)
ReasoningStrategies = Literal["zero-shot-react", "plan-and-solve"]
def load_agent(
tool_names: list[str],
strategy: ReasoningStrategies = "zero-shot-react" ) -> Chain:
llm = ChatOpenAI(temperature=0, streaming=True)
tools = load_tools(
tool_names=tool_names,
llm=llm
)
if strategy == "plan-and-solve":
planner = load_chat_planner(llm)
executor = load_agent_executor(llm, tools, verbose=True)
return PlanAndExecute(planner=planner, executor=executor, verbose=True)
return initialize_agent(
tools=tools, llm=llm, agent=AgentType.ZERO_SHOT_REACT_DESCRIPTION, verbose=True
)
完整的代码实现可以在GitHub上question_answering包内的对应版本中找到。如果在处理过程中遇到输出解析错误,可以通过在initialize_agent()方法中设置handle_parsing_errors属性来解决。
接下来,我们在Streamlit中通过一个单选按钮创建一个新变量,并通过load_agent()函数传递这个变量:
strategy = st.radio(
"Reasoning strategy",
("plan-and-solve", "zero-shot-react")
)
您可能已经注意到,load_agent()方法需要一个字符串列表tool_names作为输入。这个列表也可以通过用户界面进行选择:
tool_names = st.multiselect(
'Which tools do you want to use?',
[
"google-search", "ddg-search", "wolfram-alpha", "arxiv", "wikipedia", "python_repl", "pal-math", "llm-math"
],
["ddg-search", "wolfram-alpha", "wikipedia"])
在应用中,代理的加载方式如下:
agent_chain = load_agent(tool_names=tool_names, strategy=strategy)
为了执行这个代理,我们需要在终端运行特定的Streamlit命令:
PYTHONPATH=. streamlit run question_answering/app.py
运行后,我们将看到Streamlit如何启动应用。通过访问默认的URL,我们可以在浏览器中查看到用户界面:
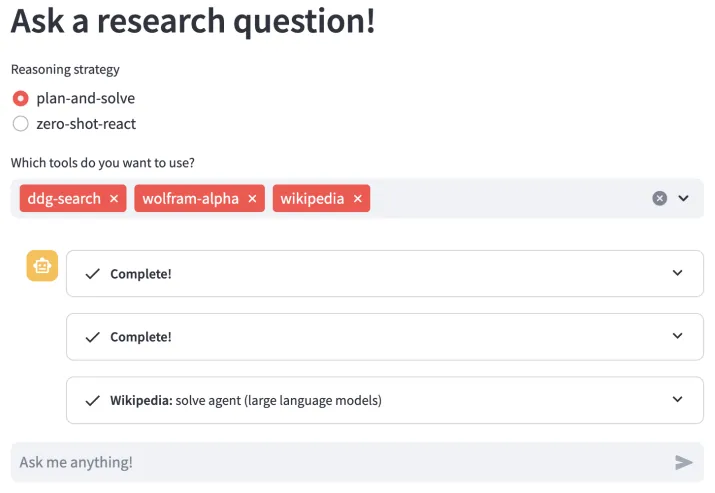
请在浏览器中打开应用程序,查看关于“在大型语言模型(LLM)的上下文中,计划求解代理是什么?”的各个解答步骤。以下是代理给出的答案,但请注意,结果可能不是完全准确的:
- LLM定义:LLM是经过大量文本数据训练的人工智能模型,能够根据输入生成类似人类的文本。
- LLM中计划的概念:在大型语言模型中,计划是指模型为解决问题或回答问题而生成的一系列结构化步骤。
- LLM中求解代理的概念:求解代理是一种LLM,作为代理运行,负责生成解决问题或回答问题的计划。
- 计划和求解代理在LLM中的重要性:计划和求解代理有助于整理模型的思维过程,为问题解决或问答任务提供有序的方法。
- 用户原始问题的回答:在大型语言模型的上下文中,计划是由求解代理生成的结构化步骤或概要,用于解决问题或回答问题。求解代理是大型语言模型的一个组件,负责生成这些计划。
首先,我们需要对LLM进行查找,动作如下:
Action:
{
"action": "Wikipedia",
"action_input": "large language models"
}
我们尚未讨论问题回答的另一个方面,即在这些步骤中使用的提示策略。提示技术,包括少数示例链式思考(CoT)提示,它通过逐步推理引导LLM;零示例CoT提示,它在没有示例的情况下指导LLM逐步思考;CoT提示,旨在通过示例帮助理解推理过程。
在计划求解中,复杂任务被细分为子任务并依次执行,这可以通过更详细的指令来增强,例如强调关键变量和常识,以提高推理质量。
可以在 https://github.com/blockpipe/BlockAGI 找到使用LangChain进行高级增强信息检索的示例,该项目受到BabyAGI和AutoGPT的启发。
我们对推理策略的介绍到此结束。虽然所有策略都可能遇到计算错误、遗漏步骤或语义误解等问题,但它们有助于提升生成的推理步骤的质量,增强问题解决的准确性,并提高LLM处理各种推理问题的能力。
总结
在本文中,我们首先探讨了幻觉问题和自动事实核查,旨在提升大型语言模型(LLMs)的可靠性。我们实施了一些简单的方法来提高LLM输出的准确性。接着,我们探讨并实施了提示策略,以便更好地分解和总结文档,这对于理解和分析大型研究文章非常有帮助。同时,我们也注意到频繁调用LLM可能会导致成本增加,因此我们特别讨论了令牌使用的问题。
OpenAI的API提供了函数调用功能,这可以用于文档中的信息提取,例如,我们实现了一个简单的简历解析器来展示这一功能。此外,工具和函数调用不仅限于OpenAI,它们的发展使得模型能够通过与真实系统的交互,执行更复杂的任务。这些方法提高了AI助手的能力和可靠性。通过LangChain,我们能够实现调用工具的不同代理,例如,我们用Streamlit创建了一个应用程序,它可以通过搜索引擎或Wikipedia等外部工具来辅助回答研究问题。与检索增强生成(RAG)不同,工具通过直接查询数据库、API和其他结构化外部资源来提供上下文增强。
我们还研究了代理决策的不同策略,特别是在决策时机上的区别。我们在Streamlit应用程序中实现了计划求解和零射击代理两种策略。
最后,本文要点总结如下:
- 🔍 幻觉与事实核查:讨论了如何提升LLMs的可靠性。
- 📄 文档总结:实施提示策略,简化大型文档的理解和分析。
- 💡 令牌使用:特别讨论了频繁调用LLM可能导致的成本问题。
- 🛠️ OpenAI API函数:用于文档信息提取,例如简历解析。
- 🔗 工具与函数调用:发展使模型能够执行复杂任务,提高AI助手的能力和可靠性。
- 🔍 LangChain代理:实现调用工具的不同代理,辅助研究问题的回答。
- 🔑 检索增强生成(RAG):与工具提供的上下文增强不同,使用向量搜索进行语义相似性。
- 📊 决策策略:研究了代理决策的不同策略,特别是在决策时机上的区别。
- 📈 计划求解与零射击代理:在Streamlit应用程序中实现的两种策略。
思考
- 大型语言模型(LLMs)如何用于文档摘要?
- 密度链是什么?
- LangChain装饰器及LangChain表达式语言是什么?
- 在LangChain中,map-reduce是如何实现的?
- 我们如何计算所使用的令牌数量,以及为何这样做是必要的?
- 指令调整与函数调用及工具使用有何关联?
- 请列举一些LangChain中可用的工具。
- 描述两种代理架构。
- Streamlit是什么,我们为何要使用它?
- 自动化事实核查的工作原理是什么?
参考
- 构建高效的信息助手,访问密码:theforage.cn
- Building Capable Assistants,访问密码:theforage.cn
加入AIPM🌿社区
